2025年4月,百度地图正式发布V21版本,全面升级为”智驾级导航”。到2026年5月,版本迭代到21.16.0,还在百度Create大会上发布了面向车企的DuDuClaw座舱智能体平台。
十多年前我写过一篇《开发者眼中的百度LBS开放平台》,记录了那场开发者大会:Openmap计划、王文海讲的共赢模式、张宝龙介绍Open API。那时候的想法很简单——希望百度能给开发者更多空间,希望本土LBS能有大发展。
今天再看百度地图,早已不是当年那个”提供API、你自己接入”的开放平台了。
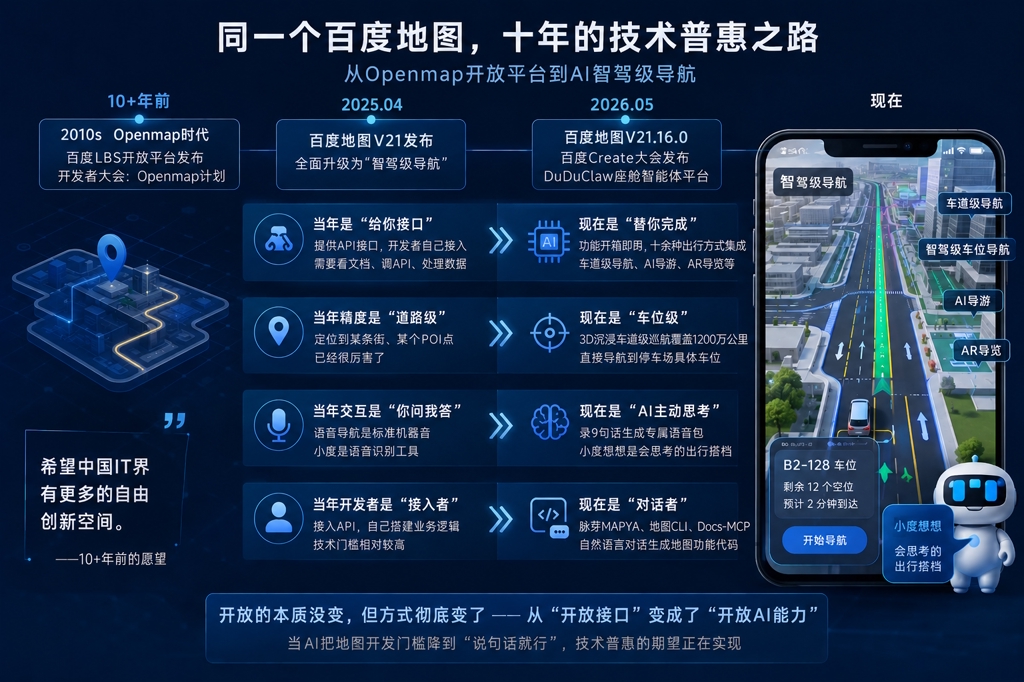
当年是”给你接口”,现在是”替你完成”。
那时候我们要看接入流程文档、调API、处理坐标系、自己搭业务逻辑。LBS应用的技术门槛确实在降低,但活儿还是开发者自己干。今天百度地图App直接集成了十余种出行方式,车道级导航、智驾级车位导航、AI导游、AR导览——这些当年需要开发者自己拼凑的功能,现在用户开箱即用。
当年精度是”道路级”,现在是”车位级”。
那时候Openmap能帮你定位到某条街、某个POI点,已经很厉害了。今天百度地图的3D沉浸车道级巡航覆盖1200万公里道路,不仅能识别你在哪条车道,还能直接导航到停车场里的具体车位,实时告诉你哪里有空位。
当年交互是”你问我答”,现在是”AI主动思考”。
那时候语音导航是标准的机器音,今天录9句话就能生成你自己的语音包,全场景播报。当年的小度只是语音识别工具,今天的”小度想想”是”会思考的出行搭档”。
当年开发者是”接入者”,今天是”对话者”。
今年百度Create大会发布的脉芽MAPYA、百度地图CLI、Docs-MCP,意味着开发者不需要再啃API文档,用自然语言对话就能生成地图功能代码。开放的本质没变,但方式彻底变了——从”开放接口”变成了”开放AI能力”。
当年我在文章末尾写:”希望中国IT界有更多的自由创新空间。”今天当AI把地图开发门槛降到”说句话就行”,那个期望好像真的实现了,只是实现的方式超出了当年的想象。
同一个百度地图,从Openmap到AI智驾,走了十多年。当年站在台下的开发者,今天成了用手机导航到车位的普通用户。技术普惠这件事,希望百度地图可以越做越好。
